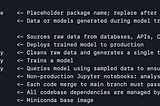
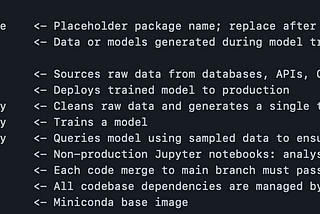
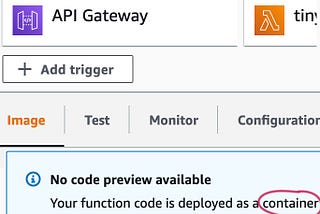
Adam NovotnyMachine Learning Docker TemplateThis post was originally published on my website adamnovotny.comDec 19, 2021Dec 19, 2021
Adam NovotnyinAnalytics VidhyaKeras LSTM Forecasting Using Synthetic DataThis post was originally published on my website adamnovotny.comNov 14, 2021Nov 14, 2021
Adam NovotnyinAnalytics VidhyaGlobal Temperature Forecast Using Prophet and CO2In this article I will leverage the global temperate dataset I discussed previously to make a temperature forecast using Facebook Prophet…May 24, 2021May 24, 2021
Adam NovotnyDynamic HTML with Python, AWS Lambda, and ContainersThis article is an extension of my previous article describing a similar deployment process using native AWS Lambda tools. However, Amazon…Mar 27, 2021Mar 27, 2021
Adam NovotnyGoogle Colab and Auto-sklearn with ProfilingThis article is a follow up to my previous tutorial on how to setup Google Colab and auto-sklean. Here, I will go into more detail that…Mar 20, 2021Mar 20, 2021
Adam NovotnyMachine Learning NotesThis collection of ML notes is continuously updated:Dec 23, 2020Dec 23, 2020
Adam NovotnyGoogle Colab and AutoML: Auto-sklearn SetupAuto ML is fast becoming a popular solution to build minimal viable models for new projects. A popular library for Python is Auto-sklearn…Dec 4, 20201Dec 4, 20201
Adam NovotnyGoogle Paper: 24/7 by 2030Google released a white paper describing how the company intends to generate all of its electricity needs from renewable energy sources by…Oct 31, 2020Oct 31, 2020
Adam NovotnyServing Dynamic Web Pages using Python and AWS LambdaWhile AWS Lambda functions are typically used to build API endpoints, at their core Lambda functions can return almost anything. This…Jul 25, 20201Jul 25, 20201
Adam NovotnyCustom scikit-learn PipelineI have gone through many iterations of what my preferred scikit-learn custom pipeline looks like. As of 6/2020, here is my latest…Jun 25, 2020Jun 25, 2020